本文共 16741 字,大约阅读时间需要 55 分钟。
前言
1970年,Rudolf Bayer教授在《Organization and Maintenance of Large Ordered Indices》一文中提出了B树[1],从它基础上演化产生了B+树。B+树采用多叉树结构,降低了索引结构的深度,避免传统二叉树结构中绝大部分的随机访问操作,从而有效减少了磁盘磁头的寻道次数,降低了外存访问延迟对性能的影响。它保证树节点中键值对的有序性,从而控制search/insert/delete/update操作的时间复杂度在O(log(n))的范围内。鉴于上述优势,B+树作为索引结构的构建模块,被广泛应用在大量数据库系统和存储系统中,其中就包括MySQL。
索引结构作为影响系统性能的关键因素之一,对数据库系统在高并发场景下的性能表现具有重大的影响。从上世纪70年代B+树提出至今,学术界有大量论文尝试优化B+树在多线程场景下的性能,这些文章被广泛发表在数据库/系统领域顶级会议VLDB/SIGMOD/EuroSys上。然而,由于过长的时间跨度(1970s-2010s,40多年时间),目前网络上缺乏讨论B+树并发机制的较为系统的分析文章,尤其在中文文章方面。本文尝试选取不同时间点上几个具有代表性的研究工作,分析B+树并发控制机制的发展过程,探讨B+树并发机制在MySQL中的发展及优化。由于篇幅和时间限制,本文的部分观点可能尚不完善,欢迎读者指正。读者也可根据文章末尾的引用论文,深入阅读相关工作。
文章目录:
- B+树的数据结构及基础操作
- B+树并发控制机制的基本要求
- B+树并发控制机制的发展历程(从1970s至今)
- Mysql5.7的B+树并发控制机制
- Lock-Free B+树 \u0026amp; 总结
B+树的数据结构及基础操作
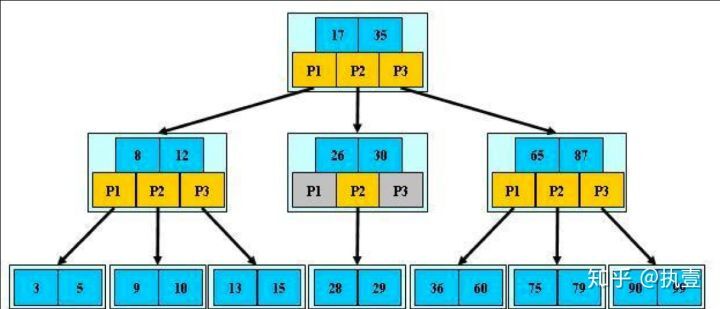
一棵传统的B+树需要满足以下几点要求:
- 从根节点到叶节点的所有路径都具有相同的长度
- 所有数据信息都存储在叶节点上,非叶节点仅作为叶节点的索引存在
- 根结点至少拥有两个键值对
- 每个树节点最多拥有M个键值对
- 每个树节点(除了根节点)拥有至少M/2个键值对
一棵传统的B+需要支持以下操作:
- 单键值操作:Search/Insert/Update/Delete(下文以Search/Insert操作为例,其它操作的实现相似)
- 范围操作:Range Search
由于篇幅所限,本文假设读者对B+树的基础结构和操作原理有一定的了解,仅对B+树的基本结构和操作做简单介绍,有需求的读者可根据引用[1]的文章自行阅读。
B+树并发控制机制的基本要求
按照笔者的理解,正确的B+树并发控制机制需要满足以下几点要求:
正确的读操作:
- R.1 不会读到一个处于中间状态的键值对:读操作访问中的键值对正在被另一个写操作修改
- R.2 不会找不到一个存在的键值对:读操作正在访问某个树节点,这个树节点上的键值对同时被另一个写操作(分裂/合并操作)移动到另一个树节点,导致读操作没有找到目标键值对
正确的写操作:
- W.1 两个写操作不会同时修改同一个键值对
无死锁:
- D.1 不会出现死锁:两个或多个线程发生永久堵塞(等待),每个线程都在等待被其他线程占用并堵塞了的资源
不管B+树使用的是基于锁的并发机制还是Lock-Free的并发机制,都必须满足上述需求。在下文中,本文将针对不同的并发机制,分别阐述它们是如何满足上述要求,并达到了什么样的优化效果。
B+树并发控制机制的发展历程(从1970s至今)
本文使用的一些标记
首先,介绍本文伪代码中需要使用的一些标记。
SL (Shared Lock): 共享锁 — 加锁
SU (Shared Unlock): 共享锁 — 解锁XL (Exclusive Lock): 互斥锁 — 加锁XU (Exclusive Unlock): 互斥锁 — 解锁SXL (Shared Exclusive Lock): 共享互斥锁 — 加锁SXU (Shared Exclusive Unlock): 共享互斥锁 — 解锁R.1/R.2/W.1/D.1: 并发机制需要满足的正确性要求safe nodes:判断依据为该节点上的当前操作是否会影响祖先节点。以传统B+树为例:(1) 对于插入操作,当键值对的数量小于M时,插入操作不会触发分裂操作,该节点属于safe node;反之当键值对数量等于M时,该节点属于unsafe node;(2) 对于删除操作,当键值对的数量大于M/2时,不会触发合并操作,该节点属于safe node;反之当键值对数量等于M/2时,该节点属于unsafe node。当然,对于MySQL而言,一个节点是否是安全节点取决于键值对的大小和页面剩余空间大小等多个因素,详细代码可查询MySQL5.7的btr_cur_will_modify_tree()函数。 基础并发控制机制(MySQL5.6)
MySQL5.6以及之前的版本采用了一种较为基础的并发机制:它采用了两种粒度的锁:
(1)index粒度的S/X锁;(2)page粒度的S/X锁(本文等同于树节点粒度)。前者被用来控制对树结构访问及修改操作的冲突,后者被用来控制对数据页访问及修改操作的冲突。下文将以伪代码的形式详细分析读写操作的过程。
/* Algorithm1. 读操作 */ SL(index) Travel down to the leaf node SL(leaf) SU(index) Read the leaf node SU(leaf)
在Algorithm 1中,读操作首先对整个B+树加S锁(step1),其次访问树结构直到对应的叶节点(step2),接着对叶节点的page加S锁(step3),再释放index的S锁(step4),然后访问叶节点的内容(step5),最后释放叶节点的S锁(step6)。从上述步骤可以看出,读操作通过index的S锁,避免在访问到树结构的过程中树结构被其它写操作所修改,从而满足R.2的正确性要求。其次,读操作到达叶节点后先申请叶节点页的锁,再释放index的锁,从而避免在访问具体的键值对信息时数据被其它写操作所修改,满足R.1的正确性要求。由于读操作在访问树结构的过程中对B+树加的是S锁,所以其它读操作可以并行访问树结构,减少了读-读操作之间的并发冲突。
/* Algorithm2. 悲观写操作 */ XL(index) Travel down to the leaf node XL(leaf) /* lock prev/curr/next leaves */ Modify the tree structure XU(index) Modify the leaf node XU(leaf)
因为写操作可能会修改整个树结构,所以需要避免两个写操作同时访问B+树。为了解决这个问题,Algorithm 2采用了一种较为悲观的方案。每个写操作首先对B+树加X锁(step1),从而阻止了其它读写操作在这个写操作执行过程中访问B+树,避免它们访问到一个错误的中间状态。其次,它遍历树结构直到对应的叶节点(step2),并对叶节点的page加X锁(step3)。接着,它判断该操作是否会引发split/merge等修改树结构的操作。如果是,它就修改整个树结构(step4)后再释放index的锁(step5)。最后,它在修改叶节点的内容(step6)后释放了叶节点的X锁(step7)。虽然悲观写操作通过索引粒度的互斥锁满足了W.1的正确性要求,然而因为写操作在访问树结构的过程中对B+树加的是X锁,所以它会堵塞其它的读/写操作,这在高并发场景下会导致糟糕的多线程扩展性。这是否存在可优化的空间呢?请接着看下文。
/* Algorithm3. 乐观写操作 */ SL(index) Travel down to the leaf node XL(leaf) SU(index) Modify the leaf node XU(leaf)
实际上,因为每一个树节点页可以容纳大量的键值对信息,所以B+树的写操作在多数情况下并不会触发split/merge等修改树结构的操作。因此,相比于Algorithm 2中的悲观思想,Algorithm 3中采用了一种乐观思想,即假设大部分写操作并不会修改树结构。在Algorithm 3中,写操作的整个过程与Algorithm 1大致相同,它在访问树结构过程中持有树结构的S锁,从而支持其它读/乐观写操作同时访问树结构。Algorithm 3与Algorithm 1主要的区别在于写操作对叶节点持有X锁。在MySQL5.6中,B+树往往优先执行乐观写操作,只有乐观写操作失败才会执行悲观写操作,从而减少了操作之间的冲突和堵塞。不管是悲观写操作还是乐观写操作,它都通过索引粒度或者页粒度的锁避免相互之间修改相同的数据,所以满足W.1的正确性要求。
对于死锁问题,MySQL5.6采用的是“从上到下,从左到右”的加锁顺序,不会出现两个线程加锁顺序成环的现象,所以不会出现死锁的情况,满足D.1的正确性要求。
只锁住被修改的分支
虽然MySQL5.6采用乐观写操作减少了线程间的冲突,但是它的主要问题在于:即使其它读写操作访问的是树结构的不同分支,在实际执行过程中不会产生相互间的影响,但是悲观写操作依然会堵塞其它所有读/写操作,直到树结构修改完成,这导致了过高的堵塞开销。是否存在一种并发机制,它只锁住B+树中被修改的分支,而不是锁住整个树结构呢?答案是肯定的,《B-trees in a system with multiple users》在1976年就已经提出了一种可行的方案[2]。
与MySQL5.6不同,Algorithm 4-5中的算法不再使用索引粒度的S/X锁,而只使用树节点粒度的S/X锁。因为树节点粒度锁的支持,当修改树结构时,写操作不再只是粗暴地对整个索引结构加锁,而只对修改的分支加锁。首先,我们先看读操作的具体实现。
/* Algorithm4. 读操作 */ current \u0026lt;= root SL(current) While current is not leaf do { SL(current-\u0026gt;son) SU(current) current \u0026lt;= current-\u0026gt;son } Read the leaf node SU(current) 在Algorithm 4中,读操作从根节点出发,首先持有根节点的S锁(step1-2)。在(step3-7)的过程中,读操作先获得子节点的S锁,再释放父节点的S锁,这个过程反复执行直到找到某个叶节点。最后,它在读取叶节点的内容(step8)后释放了叶节点的S锁(step9)。因为读操作在持有子节点的锁后才释放父节点的锁,所以不会读到一个正在修改的树节点,不会在定位到某个子节点后子节点的键值对被移动到其它节点,因此能满足R.1/R.2的正确性要求。
/* Algorithm5. 写操作 */Writer current \u0026lt;= root XL(current) While current is not leaf do { XL(current-\u0026gt;son) current \u0026lt;= current-\u0026gt;son If current is safe do { /* Unlocked ancestors on stack. */ XU(locked ancestors) } } /* Already lock the modified branch. */ Modify the leaf and upper nodes XU(current) and XU(locked ancestors) 在Algorithm 5中,写操作同样从根节点出发,首先持有根节点的X锁(step1-2)。在step3到step10的过程中,写操作先获得子节点的X锁,然后判断子节点是否是一个安全节点(操作会引起该节点的分裂/合并等修改树结构的操作)。如果子节点是安全节点,写操作立即释放祖先节点(可能包含多个节点)的X锁,否则就会暂时保持父节点的锁,这个过程反复执行直到找到某个叶节点。当到达了叶节点后,写操作就已经持有了修改分支上所有树节点的X锁,从而避免其它读/写操作访问该分支(step11),满足W.1的正确性要求。最后,它在修改这个分支的内容(step12)后释放了分支的锁(step13)。
对于死锁问题,Algorithm 4-5同样采用的是“从上到下”的加锁顺序,满足D.1的正确性要求。值得注意的是,Algorithm 4-5中提出的并发机制被使用到MySQL5.7中,详细情况将在后文中说明。
SX锁横空出世
Algorithm 4-5提出的并发机制的主要问题在于它其实依然采用了一种较为悲观的思想:写操作在到达被修改分支之前,对途径的树节点加的是X锁,这在一定程度上阻塞了其它操作访问对应的树节点。当这个写操作需要频繁将树节点从磁盘读取到内存产生较高的IO延迟时,这个堵塞开销会更高。如前文所述,在大部分情况下,写操作并不会修改途径的非叶节点,所以不会对访问相同节点的读操作产生影响。但是,如果写操作到达某个子节点时发现子节点是unsafe的,它必须一直持有父节点的锁,否则父节点可能已被其它写操作所修改。因此出现一个问题,是否存在一种位于S锁与X锁之间的SX锁,它可以堵塞其它的SX/X加锁操作(写操作),但可以允许S加锁操作(读操作),并且当它确定要修改该节点时可升级为X锁堵塞其它读写操作。
Rudolf Bayer教授于1977年在《Concurrency of operations on B -trees》一文中提出了SX锁,SX锁被使用到了MySQL5.7中,详细情况将在后文中说明。此外,这篇文章提出了先尝试乐观写操作,再执行悲观写操作的优化策略,如前文所述,该策略已经应用到MySQL5.6中。
/* Algorithm6. 写操作 */ current \u0026lt;= root SXL(current) While current is not leaf do { SXL(current-\u0026gt;son) current \u0026lt;= current-\u0026gt;son If current is safe do { /* Unocked ancestors on stack. */ SXU(locked ancestors) } } XL(modified nodes) /* SX-\u0026gt;X, top-to-down*/ /* Already lock the modified branch. */ Modify the leaf and upper nodes XU(current) and XU(locked ancestors) 因为SX锁只与写操作有关,所以本章节使用了与Algorithm 4相同的读操作,只介绍不同的写操作。Algorithm 6与在Algorithm 5十分相似,主要的区别在于,Algorithm 6在step2,4,8中使用SX锁取代了X锁。到达某个叶节点后,它再将修改分支上的SX锁升级为X锁。这样做的好处在于,在写操作将影响分支上的锁升级为X锁前,所有读操作都可以访问被这个写操作访问过的非叶节点,从而减少了线程之间的冲突。由于SX锁的存在,不会出现多个写操作修改同一个分支的情况,从而满足了W.1的正确性要求。
锁,请你使用地尽可能少一些
前文中的并发控制机制在很大程度上减少了线程间的冲突,但是依然存在一个问题:不论读/写操作,它们在访问一个树节点前都需要对树节点加S/SX/X锁。频繁加锁产生的开销,在核数越来越多/硬件性能越来越强的今天,开始慢慢成为一个不可忽略的开销,尤其在内存数据库/内存系统中。发表在2001年数据库领域顶级会议VLDB的文章《Cache-Conscious Concurrency Control of Main-Memory Indexes on Shared-Memory Multiprocessor Systems》详细说明了这个问题[6]。
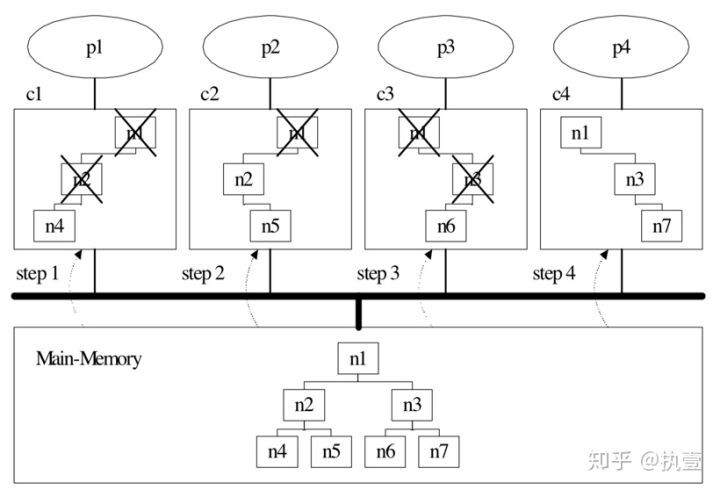
频繁加锁操作在多核处理器上会产生Coherence Cache Miss过高的问题。以上图为例,假设有4个处理器(p1/p2/p3/p4),每个处理器分别有自己的private cache(c1/c2/c3/c4)。为了便于说明,同样假设有4个线程(p1/p2/p3/p4),与处理器一一绑定。下文中的n1/n2/n3/n4/n5/n6/n7可以指的是树节点的锁,也可以指代树节点,两者在下文叙述中等价。下面开始说明为什么频繁加锁会引入较高的Coherence Cache Miss开销:
a. p1访问树节点n1/n2/n4,然后将它们放在缓存c1;
b. p2访问树节点n1/n2/n5,然后将它们放在缓存c2;c. p2修改的S锁会导致缓存c1中的n1/n2失效;d. 注意即使缓存c1中有足够大的空间,这些缓存缺失操作依然会发生;e. p3访问树节点n1/n2/n5,然后导致缓存c2中的n1/n2失效;f. p4访问树节点n1/n3/n7,然后导致缓存c3中的n1/n3失效;如上图所示,不论哪个线程访问树结构,由于它在访问每个树节点时都需要修改对应的树节点锁,这会导致其它private cache里的数据失效,带来过高的缓存一致性开销。随着多核处理器的发展,以NUMA架构为基础的多核处理器产品在数据中心中被广泛使用,而这类产品上的缓存一致性开销将会成为更加严重的问题。为了更加明确地说明这一点,本文从Intel官方数据中引用了部分数据[5]。
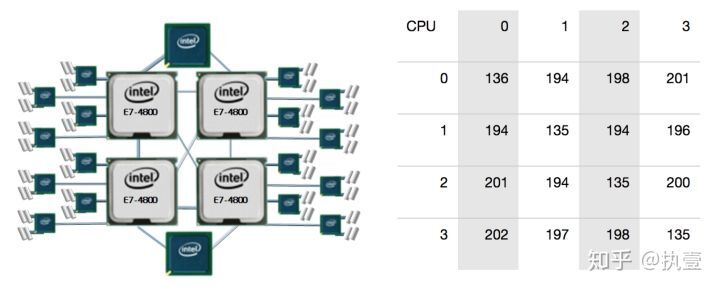

上文分别列举了E7-4800和E5-4600两款处理器的参数,我们可以看到跨socket的访问延迟高达200-300ns。大家都知道,访问一次内存的操作仅为50-100ns,而加锁操作导致的跨socket同步操作带来的延迟远高于访存操作。当系统中存在大量cache coherence miss时,势必会提高处理器/总线的资源消耗,产生较高的延迟开销,这在内存数据库/内存系统中更是一个不可忽略的问题。那是否可以减少加锁的频率,在保证正确性的基础上减少锁操作带来的开销呢?答案依然是肯定的。
前文中所述的并发机制,往往采用自顶向下的加锁策略,在安全地获取到子节点的锁后释放父节点的锁。然而我们很容易发现,这种加锁方式依然是十分悲观的:大部分获取到的锁其实是无意义的,尤其在树的上层,因为离根节点越近的树节点被更新的概率越低。因此,如果存在一种自底向上加锁的策略,只有在树节点分裂或者合并或者删除的情况下向上加锁,只对被修改的树节点加锁,就可以在很大程度上减少加锁的范围和频率,从而提高B+树的多线程扩展性。为了实现这个目标,我们首先需要支持在不持有锁的状态下从根节点访问到叶节点的功能。想知道这个目标是如何实现的,请耐下性子接着看下文 :D。
Blink树,对后世影响深远的多线程B+树
1981年,数据库领域顶级期刊TODS上发表了一篇文章《Efficient locking for concurrent operations on B-trees》[4],介绍Blink树`这一简单有效的多线程B+树。由于年代深远,Blink-Tree当时假设的计算机模型与现在主流的计算机并不相同。笔者对其的总结是:Blink树假设访问树节点的读写操作是原子性的,读操作不会读到写操作修改到一半的状态(即已满足R.1正确性要求),但写操作之间修改同一份数据时会出现冲突。具体的计算机模型读者可查阅[4]这篇论文,这一假设存在的问题会在后文中得到解决。Blink树提出为每一个树节点配置一个右指针。别小看这么简单的一个设计,它的出现使得在无锁状态下自顶向下的访问策略+自底向上的加锁策略成为可能,对后续多种多线程B+树的设计产生深远的影响。
/* Algorithm7. 读操作 */ current \u0026lt;= root While current is not leaf do { current \u0026lt;= scanNode(current, v) current \u0026lt;= current-\u0026gt;son } /* Keep move right if necessary. */ /* Deal with the leaf node. *//* scanNode函数 */ Func scanNode(node* t, int v) { If t-\u0026gt;next-\u0026gt;key[0] \u0026lt;= v do t \u0026lt;= scanNode(t-\u0026gt;next, v) return t; } 在Algorithm 7中,读操作从根节点出发,遍历整个树结构,直到找到某个叶子节点(step1-5)。注意在这个过程中,读操作并不持有锁。Algorithm 7的特殊之处在于在每到达一个子节点后,它都会调用scanNode函数,这个函数就是Blink树的精髓所在。因为读操作在遍历树结构的过程中不持有锁,这导致它访问的某个树节点可能被其它写操作所分裂或者删除。当读操作准备访问某个子节点时,这时这个子节点被其它写操作分裂,可能导致目标键值对被移动到子节点的兄弟节点,导致读操作找不到一个其实存在的键值对,就发生了R.2错误。当读操作访问某个子节点的过程中,这个子节点被其它写操作删除,那么这个读操作可能会发生dangling pointer的错误。
前文提到,Blink树提出为每一个树节点配置一个右指针,这个右指针为读操作提供了另一种方式去访问子节点的右兄弟节点。Blink树规定树的分裂操作顺序必然是从左至右,因此目标键值对只有可能被分裂到子节点的右兄弟节点。在(step8-12)中说明了scanNode的实现。大致的过程就是读操作会判断子节点的右兄弟节点的最小值是否大于它正在查找的目标键值,如果不是说明目标键值对在右兄弟节点或者更右边的节点,指针就会往右走,直到找到某个右兄弟节点的最小值大于目标键值。因此,右指针的存在帮助读操作能定位到真实存在的所有键值对,从而满足R.2的正确性要求。
对于删除操作,年代久远的Blink树采用一种比较粗暴的方式(也许它认为删除操作的执行次数相对较少:D)。当发生删除操作时,它采用index粒度的X锁,堵塞其它读/写操作,避免了dangling pointer错误的发生。
/* Algorithm8. 写操作 */ current \u0026lt;= root While current is not leaf do { current \u0026lt;= scannode(current, v) stack \u0026lt;= current current \u0026lt;= current-\u0026gt;son } XL(current) /* lock the current leaf */ moveRight(current) DoInsertion: If current is safe do insert(current) and XU(current) else { allocate(next) shift(next) + link(next) modify(current) oldnode \u0026lt;= current current \u0026lt;= pop(stack) XL(current) moveRight(current) XU(oldnode) goto DoInsertion; } 虽然Blink树的写操作相对复杂一些,但是对读操作的原理有了一定的理解后,写操作理解起来也不再那么复杂。写操作使用和读操作类似的方式定位到目标叶节点current并加锁(step1-8)。为了支持自底向上加锁,写操作遍历过程中将访问到的树节点压入栈stack中。如果叶节点是安全节点,直接插入后释放锁就可以了(step10-11)。如果叶节点不是安全节点,就分配一个新的next节点,将叶节点的数据移动到next节点,修改current节点并将右指针指向next节点(step13-15)。然后,写操作从栈中弹出上一层的父节点并加锁(step16-18)。由于父节点也可能被分裂,所以也需要通过moveRight函数移动到正确的上一层节点(step19),然后重复上述的DoInsertion过程。moveRight与scanNode相似,主要的区别在于前者是在加锁状态下向右走,拿到右节点的锁后可释放当前结点的锁。写操作通过树节点粒度的锁,避免了多个写操作同时修改同一个树节点,满足W.1的正确性要求。
对于死锁,由于Blink树只支持“自左向右,自底向上”加锁的策略,所以不会出现死锁的问题。
OLFIT树,版本号你值得拥有
虽然Blink树有效减少了加锁频率,但是它依然存在两个问题:1. 不实际的假设:读写树节点的操作是原子性的;2. 删除操作竟然需要锁住整个索引结构,效率太差了。针对这些问题,还是2001年VLDB上的这篇文章《Cache-Conscious Concurrency Control of Main-Memory Indexes on Shared-Memory Multiprocessor Systems》,它提出了OLFIT树,在Blink树基础上引入了版本号的概念。
/* Algorithm9. 树节点的写操作 */ XL(current) Update the node content INCREASE(version) XU(current)/* Algorithm10. 树节点的读操作 */ RECORD(version) Read the node content If node is lock, go to step1 If version differs, go to step1
Algorithm 9-10显示版本号相关的具体操作。Algorithm 9显示写操作在每个树节点上的执行过程:它首先锁住这个节点(step1),接着更新这个节点的内容(step2),然后递增树节点的版本号(step3),最后释放这个节点的锁(step4)。因为读操作在读取某个树节点时树节点可能被修改/分裂/删除,写操作通过锁告知读操作这个树节点正在被修改,通过版本号告知读操作这个树节点已经被修改。Algorithm 10显示读操作在每个树结点上的执行过程:它首先记录这个树节点的版本号(step1),再读取这个树节点的内容(step2),在读操作结束后再次读取节点的锁和版本号。如果节点的锁或者版本号发生变化,它判断自己读取的树节点可能处于不一致的中间状态,因此从(step1)重新开始执行。
/* Algorithm11. OLFIT树的读操作 */ current \u0026lt;= root While current is not leaf do { RECORD(version) next \u0026lt;= scanNode(current, v) If version/lock is not modified do current \u0026lt;= next } /* Keep move right if necessary. */ /* Deal with the leaf node. */ Algorithm 11显示了读操作的完整过程。(step1-7)的过程与Blink树相似,区别在于OLFIT树在访问每个节点时根据版本号/锁的状态判断自己是否读到正确的数据,从而避免读到修改到一半的树节点,满足R.1的正确性要求。对于删除操作,为了避免读操作正在访问的节点被其它写操作删除,OLFIT树可以采用epoch-based reclamation机制[7]。原理简单来说就是将删除操作分为逻辑删除和物理删除两个步骤,只有在确保一个树节点没有被任何操作访问时才可以回收这个树节点的物理空间。笔者曾完整实现epoch-based garbage collector,但由于篇幅和时间所限,有机会在以后的月报中再详细分析,本文对此不做赘述。感兴趣的读者可以参考引用[7]这篇文章。
此外,除了版本号操作以外,OLFIT树的写操作与Blink树相似,所以将写操作的伪代码留给读者自己思考。另外,OLFIT树的加锁顺序与Blink树一样,所以不存在死锁问题。
Masstree,B+树优化机制的集大成者
系统领域顶级会议EuroSys在2012年发表一篇文章:《Cache craftiness for fast multicore key-value storage》,提出了Masstree。Masstree融合了大量B+树的优化策略,包括单线程场景下和多线程场景下的。本文简单介绍一下Masstree采用的几个主要优化策略,具体情况可参照原论文。
在单线程场景下:
- 采用了B+树 + Tri树的混合数据结构。在传统B+树中,为了支持变长键值这一场景,B+树要么在树节点中预留很大的键值空间,然而这会导致存储空间的浪费。还有一种方式就是B+树采用定长指针指向变长键值,这节约了存储空间,负面效果就是存在大量指针访问,可能导致处理器缓存命中率的严重降低,影响索引结构的性能。为了解决这一问题,Masstree提出B+树 + Tri树的混合数据结构,将变长键值分为多个固长的部分,固长部分通过B+树组织,多个固长部分间的关系通过Tri树组织,取得了在空间利用率+性能两者间的平衡。
- 基于int类型的比较。Masstree将变长键值划分成多个固长部分,每个固长部分可以通过int类型表示,而不是char类型。由于处理器处理int类型比较操作的速度远远快于char数组的比较,因此Masstree通过int类型的比较进一步加速了查找过程。
- 预取指令。对于B+树从根节点到叶节点的遍历操作,绝大部分延迟是访存延迟(对于基于外存的B+树,则是外存延迟)造成的,所以Masstree通过预取指令减少访存延迟。
在多线程场景下:
- 双向链表:之前的OLFIT树论文并没有很清楚地说明并发删除操作的实现,Masstree通过维护双向链表,可以在树节点粒度的锁基础上实现并发删除操作。
- 消除不必要的版本号变化,减少重做开销:在OLFIT树中,任何一个树节点的操作都会导致树节点的版本号发生变化,这会导致同时访问该节点的读操作重做。然而,有一部分树节点的写操作并不会导致读操作读到一个错误的状态,所以不需要改变版本号。例如,对于更新操作,在8B范围内的更新操作是原子性的,读操作不会读到一个错误的状态;超过8B范围的更新操作也可以做成原子性的,即用指针指向超过8B范围的数据,更新操作只需要修改8B的指针就可以了;对于插入操作,传统B+树的插入操作往往会导致键值对的重排序,这需要通过版本号的变化通知读操作可能读到不一致的状态。而在Masstree中,它通过8B的permutation维护树节点键值对的有序性,避免传统B+树中键值对排序的操作,但是每个树节点最多只能容纳15个键值对。
Mysql5.7的B+树并发控制机制
在分析完B+树并发控制机制几十年的发展后,本文重新审视MySQL中B+树并发控制机制的现状。从MySQL5.6版本升级到5.7版本的过程中,B+树的并发机制发生了比较大的变化,主要包括以下几点:(1)引入了SX锁;(2)写操作尽可能只锁住修改分支,减少加锁的范围。具体伪代码如下:
/* Algorithm12. 读操作 */ SL(index) While current is not leaf do { SL(non-leaf) } SL(leaf) SU(non-leaf) SU(index) Read the leaf node SU(leaf) 在Algorithm 12中,每个读操作首先对树结构加S锁(step1),其次访问树结构直到对应的叶节点(step2-4)。这里与5.6不同之处在于,读操作对经过的所有叶节点加S锁。接着,它对叶节点的page加S锁(step5)后释放了索引结构和非叶节点的S锁(step6-7)。最后,它访问叶节点的内容(step8),释放了叶节点的锁(step9)。显而易见,读操作能满足R.1/R.2的正确性要求。
/* Algorithm13. 乐观写操作 */ SL(index) While current is not leaf do { SL(non-leaf) } XL(leaf) SU(non-leaf) SU(index) Modify the leaf node XU(leaf) Algorithm 13中的乐观写操作与Algorithm 12十分相似,主要的区别在于写操作对叶节点加X锁。
/* Algorithm14. 悲观写操作 */ SX(index) XL(modified branch) XL(leaf) /* lock prev/curr/next leaf */ Modify the tree structure XU(modieid branch) SXU(index) Modify the leaf node XU(leaf)
在Algorithm 14中,写操作首先对树结构加SX锁(step1),然后使用和Algorithm 6相似的方式在遍历树结构的过程中对被影响的分支加X锁(step2)。然后,它对叶节点加X锁(step3),然后修改树结构后释放非叶节点和索引的锁(step4-6),最后修改叶节点并释放锁(step7-8)。写操作和无死锁的正确性与前文相似,不做赘述。相比于MySQL5.6,5.7中的悲观写操作不会再锁住整个树结构,而是锁住被修改的分支,从而没有冲突的读操作可以并发执行,减少了线程之间的冲突。
然而,将之前几种B+树并发控制机制与MySQL5.7相比,读者不免会有几个疑惑:
[1] 为什么在页锁的基础上还需要索引锁?
[2] 为什么读/乐观写操作在持有索引锁后,还需要一直对非叶节点加锁?[3] MySQL是否可以像Masstree/OLFIT树/Blink树一样,自底向上加锁,减少加锁开销?如果可以,又有多大的收益?MySQL中的索引结构已经不再是一棵普通的B+树,它需要支持spatial index这样更加复杂的索引结构,需要在history list过大的时候优先支持purging线程,存在需要锁住左-当前节点-右节点这样的情况,所以它依赖索引的S/SX/X锁来避免有两个写操作同时修改树结构。此外,它还需要支持类似modify_prev/search_prev等相对复杂的回溯操作,所以需要对非叶节点加锁,避免被其它操作所修改。并且,一个实例可能存在多个聚集索引和二级索引,MySQL中B+树考虑的情况变得十分复杂。如何在现有MySQL基础上提高索引结构的多线程扩展性,请持续关注POLARDB数据库后续的工作。
Lock-Free B+树 \u0026amp; 总结
索引结构作为影响数据库系统性能的关键模块,对数据库系统在高并发场景下的性能表现具有重大影响。本文以B+树并发机制的几个代表性工作为例,深入分析了并发机制的发展和现有系统中可能存在的改进空间,希望大家看完以后有一定的收获。随着多线程索引结构的不断研究,学界已经出现了几种Lock-Free B+树的设计,其中有几种设计受到了工业界的广泛关注,甚至已经使用到真实产品中。由于本文篇幅所限,在后续的月报中,我们还会详细分析以Bw-Tree为代表的Lock-Free B+树,并且剖析其它类型索引结构的原理和发展(例如LSM-Tree,SkipList,Hash等等),请持续关注阿里云数据库内核团队!
作者简介
胡庆达,花名执壹,清华大学计算机系博士,阿里云POLARDB数据库内核研发工程师。为了高并发场景下更加优异的性能,POLARDB一直在努力,欢迎使用POLARDB!欢迎加入POLARDB!文章首发地址(阿里云数据库内核团队月报):
引用
[1] Bayer R, Mccreight E. Organization and maintenance of large ordered indices[C]// ACM Sigfidet. ACM, 1970:107-141.[2] Samadi B. B-trees in a system with multiple users ☆[J]. Information Processing Letters, 1976, 5(4):107-112.[3] Bayer R, Schkolnick M. Concurrency of operations on B -trees[J]. Acta Informatica, 1977, 9(1):1-21.[4] Lehman P L, Yao S B. Efficient locking for concurrent operations on B-trees[J]. Acm Transactions on Database Systems, 1981, 6(4):650-670.[5] Memory Latencies on Intel® Xeon® Processor E5-4600 and E7-4800 product families [6] Cha S K, Hwang S, Kim K, et al. Cache-Conscious Concurrency Control of Main-Memory Indexes on Shared-Memory Multiprocessor Systems[J]. Proc of Vldb, 2001:181–190.[7] K. Fraser. Practical lock-freedom. Technical Report UCAM- CL-TR-579, University of Cambridge Computer Laboratory, 2004.[8] Mao Y, Kohler E, Morris R T. Cache craftiness for fast multicore key-value storage[C]// ACM European Conference on Computer Systems. ACM, 2012:183-196.转载地址:http://dauyx.baihongyu.com/